Last time I covered a section on clustering, a group of unsupervised learning methods – so called because they are not given the class memberships of the data$$^\dagger$$. Don’t worry, I will do more posts on clustering soon. For now I wanted to give a quick overview of what supervised methods look like. For that, let’s look at the statistics of hockey players!
$$\dagger$$: this is a gross generalisation. More formally, for some dataset $$\mathbf{X}$$, if we are trying to predict an output variable $$\mathbf{Y}$$, we use supervised learning methods, otherwise unsupervised learning methods.
Hockey (on ice, obviously!) is a game where we have 5 skaters and 1 goalie per rotation. The 5 skaters can be divided into three$$^\ddagger$$ subclasses:
- The wingers (LW, RW)
- The centre (C)
- Defensemen (D)
$$\ddagger$$: the centre and wingers can also be bundled up as forwards.
Typically, each skater’s actions are recorded, which include:
- Goal(s) scored, assist(s) made [i.e. did the player make a pass leading up to the goal?]
- Penalties in minutes (infringements typically lead to 2 minute bans from the game)
- Ice time in 5-on-5 or ‘penalty kill’ situations
- Shots blocked etc.
Usually by looking at these statistics, one can have an approximate idea of the position a given hockey player plays. To many, this might seem like a pretty easy problem. Surely forwards are supposed to score goals! Defensemen are supposed to block shots!
Wait, so why do you want to know a player’s position?
Predicting a player’s position is perhaps not the first classification that comes to mind. However, it’s useful for something like fantasy sports leagues. In fantasy sports, you typically have roster slots for n centres, m defensemen, and q wingers. Using those constraints, you want to (usually) maximise every statistical category.
For example, if a fantasy team has a bunch of goal-scoring centremen, which position player do we pick out next to max out the penalties in minutes category? Simultaneously, which position also happens to maximise the number of assists? Do we pick up a defenseman, or a gritty right wing?
Hockey is slightly more complex than meets the eye. Typically, being a defenseman or forward can largely constrain your statistical profile; there are some defensemen that are very talented on offense (e.g. Morgan Reilly), and some forwards who are tougher, and deployed on a “checking” line to provide strength.
(This is Morgan Reilly.)
So, how can we predict positions using stats? Let’s find out.
If you have 30 seconds…
- This post is really a demo of various supervised learning methods. See table below for a quick overview.
- The algorithm of choice is often dependent on use case, and you should consider questions like:
- What is the distribution of your output?
- How can we interpret the model?
If you have 10 minutes…
- Read on. I’ve tried to section this entry based on what bits you might be interested in. This post is very much intended to be a whirlwind tour of the various supervised learning methods, rather than a deep-dive.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
Data cleanup
# Read in the data from Kaggle
df = pd.read_csv("game_skater_stats.csv")
# We'll use this later.
pinfo = pd.read_csv("player_info.csv")
df.head(3)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
The skater stats are given per player (player_id), and per game (game_id) that they have played. We know from some good documentation that:
- The first four digits represent the season (e.g. 2010-2011 season)
- The next two digits represent whether the game was held in the regular season or playoffs, etc.
What we will do is some clever pandas magic to:
- Only use regular season games
- Aggregate the statistics per player
# Filter for regular season and annotate season ID
# https://github.com/dword4/nhlapi#game-ids
df['game_id'] = df['game_id'].astype(str)
reg_season = df[df['game_id'].apply(lambda x: x[4:6] == "02")].copy()
reg_season['Season'] = reg_season['game_id'].apply(lambda x: x[:4])
reg_season.head(3)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
# aggregate stats and use average for time; otherwise totals
# We could do this by season but we'll stick to overall totals for simplification.
aggregated_stats = reg_season.groupby('player_id').agg(
{
"game_id": len, # use this as an aggregating function to get number of games played
"timeOnIce": "mean",
"goals": "sum",
"assists": "sum",
"shots": "sum",
"hits": "sum",
"powerPlayGoals":"sum",
"powerPlayAssists": "sum",
"penaltyMinutes": "sum",
"faceOffWins": "sum",
"faceoffTaken": "sum",
"takeaways": "sum",
"giveaways": "sum",
"shortHandedGoals": "sum",
"shortHandedAssists": "sum",
"blocked": "sum",
"plusMinus": "sum",
"evenTimeOnIce": "mean",
"shortHandedTimeOnIce": "mean",
}
)
aggregated_stats.columns = ['games_played'] + list(aggregated_stats.columns[1:])
aggregated_stats.head(3)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Let’s do some more feature engineering to make our lives easier…
# Powerplay and shorthanded goals/assists are typically much lower than regular goals/assists, so it's convenient to take the sum.
# Faceoffs are typically reported in percentages, anyway.
aggregated_stats['powerPlayPoints'] = aggregated_stats['powerPlayGoals'] + aggregated_stats['powerPlayAssists']
aggregated_stats['shortHandedPoints'] = aggregated_stats['shortHandedGoals'] + aggregated_stats['shortHandedAssists']
# Since some players never take faceOffs, just stick to 0 to avoid zero division errors
percentage = (aggregated_stats['faceOffWins'] / aggregated_stats['faceoffTaken'])*100
percentage = [ _ if not np.isnan(_) else 0 for _ in percentage ]
aggregated_stats['faceOffPercentage'] = percentage
aggregated_stats.drop(columns=['powerPlayGoals', 'powerPlayAssists', 'shortHandedGoals', 'shortHandedAssists', 'faceOffWins', 'faceoffTaken']).head(3)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Finally, for each player, if they have played fewer than 41 games, let’s remove them. I chose the number 41 because there are 82 games in a season. I want to know that a player has played at least half a season’s worth of games, otherwise we would have very little data to work with.
sufficient_games = []
for n,g in aggregated_stats.groupby('player_id'):
if g['games_played'].sum() >= 41:
sufficient_games.append(n)
final_stats = aggregated_stats[aggregated_stats.index.get_level_values("player_id").isin(sufficient_games)].copy()
final_stats_players = final_stats.index.get_level_values('player_id')
final_stats.head(3)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Train, validate, test
In machine learning, training, validating, and testing your model is a fundamental piece of the puzzle. Without proper splits of your data, there is a potential to overfit your model to the training set. Furthermore, the split datasets should have similar distributions of classes so that you avoid overfitting/over-penalisation, too. For the sake of this blog, I will only split by training and testing, and make one split. There are other split strategies like $$k$$-fold cross-validation but… we won’t talk about that for now. Back to topic!
Splitting is best done using sklearn’s builtin train-test splitter:
from sklearn.model_selection import train_test_split
# Get skater data from pinfo
skaters = pinfo[pinfo['primaryPosition'] != "G"][['player_id', 'firstName', 'lastName', 'primaryPosition']].copy()
skaters = skaters[skaters['player_id'].isin(final_stats_players)]
# the stratify argument makes sure we split our dataset
# so that even though the test set is 1/3 the size of the training set
# it has a similar distribution of wingers, defensemen... etc.
# let's use a seed of 0.
training_ids, test_ids = train_test_split(skaters['player_id'], random_state = 0,
test_size = 0.25, stratify = skaters['primaryPosition'])
# get the training set of data.
# Since aggregated_stats is aggregated on both player id and season,
# we have a multi-index object. this is a way to search on one column of that index.
playerIdIndex = aggregated_stats.index.get_level_values("player_id")
# Get the training set and test set of data.
training_set = aggregated_stats[playerIdIndex.isin(training_ids)].copy()
test_set = aggregated_stats[playerIdIndex.isin(test_ids)].copy()
training_set.head(3)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
Normally for machine learning methods, we can do some form of feature selection to use the most relevant variables. I am going to do the slightly naive approach of using every possible variable for prediction. This is something that may be done in practice, though it’s not the most clever idea; variables can be correlated. Here I’m going to do what’s called a “pairplot”:
def pairplot(columns, names):
n_col = columns.shape[1]
fig, ax = plt.subplots(n_col, n_col)
short_names = {
'timeOnIce': "time",
'goals': "goals",
'assists': "assists",
'shots': "shots",
'hits': "hits",
'penaltyMinutes': "PIM",
'powerPlayPoints': "PPP",
'shortHandedPoints': "SHP"
}
# Upper-triangular matrix shows correlation between variables
for i in range(0, n_col-1):
for j in range(i+1, n_col):
ax[i,j].scatter(columns[:,i], columns[:,j])
if j - i > 0:
ax[i,j].get_yaxis().set_ticklabels([])
ax[i,j].get_xaxis().set_ticklabels([])
if i == 0:
ax[i,j].set_title("{}".format(short_names[names[j]]))
if j == n_col-1:
ax[i,j].yaxis.set_label_position("right")
ax[i,j].set_ylabel("{}".format(short_names[names[i]]))
# Diagonal contains histograms
for i in range(0, n_col):
for j in range(0, n_col):
if i != j: continue
ax[i,j].hist(columns[:,i], color = '#ffd700')
if i == 0:
ax[i,j].set_title("{}".format(short_names[names[j]]))
elif j == (n_col-1):
ax[i,j].set_xlabel("{}".format(short_names[names[j]]))
# Lower-triangular matrix is hidden
for i in range(1, n_col):
for j in range(0, i):
ax[i,j].axis("off")
return fig, ax
columns = ['timeOnIce', 'goals', 'assists', 'shots', 'hits', 'penaltyMinutes', 'powerPlayPoints', 'shortHandedPoints']
fig, ax = pairplot(training_set[columns].values, columns)
fig.set_size_inches((10,10))
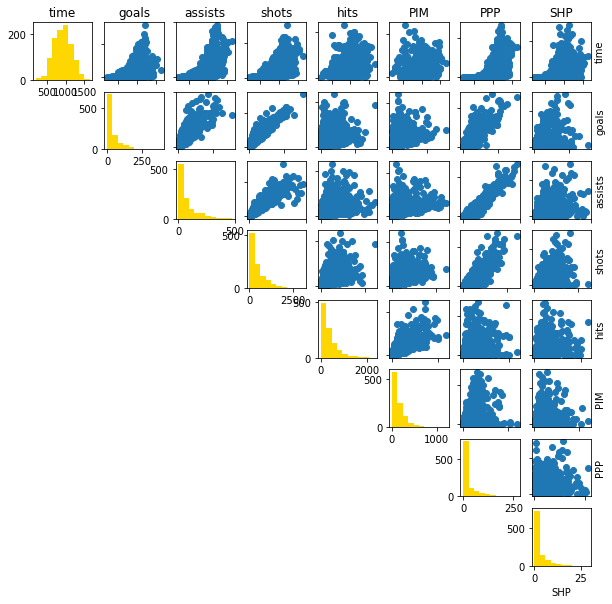
# Get the names of the players
train_skaters = skaters[skaters['player_id'].isin(training_ids)].copy()
test_skaters = skaters[skaters['player_id'].isin(test_ids)].copy()
# Create a dictionary of player IDs to positions, this makes label creation easier
train_position = dict(train_skaters[['player_id','primaryPosition']].values)
test_position = dict(test_skaters[['player_id','primaryPosition']].values)
# Get "labels" which are the hockey players' positions.
train_labels = [train_position[pid] for pid in training_set.index.get_level_values('player_id')]
test_labels = [test_position[pid] for pid in test_set.index.get_level_values('player_id')]
The “ML bit”
For this exercise, I am going to use the following supervised learning methods; below is a summary along with some pros and cons of each method. I’ve also tried to write equations where appropriate.
- Logistic Regression – Applies the logistic (binary classes) or softmax (multiple) function to a linear combination of weighted variables to predict the probability of class membership.
- Pros: Model is fairly simple to interpret, with flexibility for regularisation$$\dagger$$.
- Cons: Assumes a linear relationship between features (after logistic transformation) to class membership
- $$Pr(Y = c) = \dfrac{ e^{z_c}}{\sum_{i=1}^C e^{z_i} } ~~\mathrm{where}~~ z_i = w_iX+b_i.$$
- Naive Bayes Classifier – applies “Bayes' rule” to estimate the probability of belonging to a class.
- Pros: Typically shows good performance and is inexpensive to run.
- Cons: Assumes that each feature is independent of another
- $$Pr(Y = c|x_1, x_2… x_n) \propto P(c) \prod_{i=1}^{C} Pr(x_i|c)$$
- Random Forest Classifier – bootstraps$\ddagger$ the dataset to create a series of decision trees (the “forest”). New data is then predicted according to all the decision trees, and we take the average prediction. In the case of classification, we take the majority vote.
- Pros: Possible to trace the importance of specific features using the Gini index; very stable performance.
- Cons: Difficult to trace how the decision trees were made.
- For regression, $$\hat{f} = \dfrac{1}{T} \sum_{i=1}^{T} f_i(X_{test})$$
- Support Vector machines – finds a hyperplane that best separates classes in a dataset.
- Pros: coupled with a kernel function, can be applicable for non-linear datasets
- Cons: sometimes a “soft” margin is required
$$\dagger$$: “regularisation” is a technique where the weights of some terms are shrunk; examples include Lasso and Ridge.
$$\ddagger$$: “bootstrap” here refers to statistical bootstrapping where we sample with replacement.
# Let's get some classifiers
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB # assumes that P(x_i |y) is a Gaussian distribution
from sklearn.svm import LinearSVC, SVC
from sklearn.ensemble import RandomForestClassifier
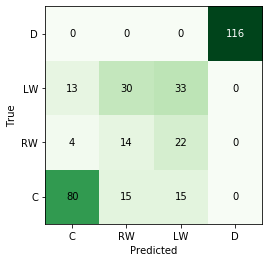
For any classification, we need some mechanism of calculating the performance of our models. There are many measures one can use, but for this exercise, we will simply calculate the accuracy, which is likely the easiest to interpret in this type of whistle-tour blog post. For a pretty visualisation, I will plot the predictions in what’s called a “confusion matrix”, which shows the distribution of predictions vs. the true answers.
from sklearn.metrics import confusion_matrix
from matplotlib import cm
def accuracy(true, pred):
assert pred.shape == true.shape, "Shape of pred and true arrays should be the same!"
return (pred == true).sum() / pred.shape[0]
def get_confusion_matrix(true,pred):
label_list = list(set(pred) | set(true))
return confusion_matrix(pred,true,labels=label_list), label_list
def plot_confusion_matrix(cmat, labels, cmap = cm.Greens):
"""
Plot a heatmap
"""
fig, ax = plt.subplots()
ax.imshow(cmat, cmap = cmap)
n_labels = len(labels)
ticklocs = np.arange(n_labels)
ax.set_xticks(ticklocs)
ax.set_yticks(ticklocs)
ax.set_xticklabels(labels)
ax.set_yticklabels(labels)
ax.set_xlim(min(ticklocs)-0.5, max(ticklocs)+0.5)
ax.set_ylim(min(ticklocs)-0.5, max(ticklocs)+0.5)
ax.set_xlabel("Predicted")
ax.set_ylabel("True")
color_threshold = np.max(cmat) * 0.75
for i in range(cmat.shape[0]):
for j in range(cmat.shape[1]):
value = cmat[i,j]
if value >= color_threshold:
ax.text(j, i, cmat[i,j], color = 'white', ha = 'center', va = 'center')
else:
ax.text(j, i, cmat[i,j], ha = 'center', va = 'center')
return fig, ax
Logistic Regression
For the purpose of this exercise I am going to use the (default) logistic regression with the $$l_2$$ penalty (also known as Ridge regression). I won’t go into too many of the mathematical details here but an important hyper-parameter of the method is the regularisation strength, $$\lambda$$. The higher the value of $$\lambda$$, this ultimately shrinks the weights closer to 0.
lm = LogisticRegression(solver='lbfgs',multi_class='multinomial', C = 0.1)
lm.fit(training_set.values, train_labels)
LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='multinomial', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
pred = lm.predict(test_set.values)
print("Accuracy of logistic regression is: {}".format(accuracy(np.array(pred), np.array(test_labels))))
Accuracy of logistic regression is: 0.7105263157894737
# plot the confusion matrix
cmat, label_list = get_confusion_matrix(test_labels,pred)
fig, ax = plot_confusion_matrix(cmat, label_list)
plt.show()
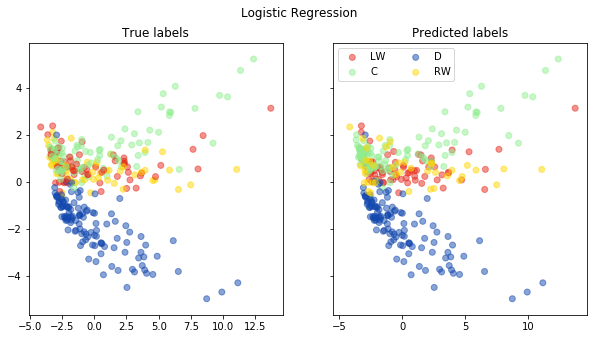
# Plot pred vs. true in a PCA plot
from sklearn.decomposition import PCA
def pca_plot(pred, method):
# scale the data
tv = (test_set - test_set.mean()) / test_set.std()
pca = PCA()
new_data = pca.fit_transform(tv)
colors = {
"RW": "#ffd700",
"D": "#1348ae",
"C": "#90ee90",
"LW": "#e8291c"
}
true_labels_to_colors = [ colors[pos] for pos in test_labels ]
pred_labels_to_colors = np.array([ colors[pos] for pos in pred ])
fig, ax = plt.subplots(1,2, sharey=True)
ax[0].scatter(new_data[:,0], new_data[:,1],
alpha = 0.5,
color = true_labels_to_colors)
#
for lab in set(pred):
pos_idx = np.argwhere(pred == lab).flatten()
ax[1].scatter(new_data[pos_idx,0], new_data[pos_idx,1],
color = pred_labels_to_colors[pos_idx],
alpha = 0.5,
label = lab)
ax[0].set_title("True labels")
ax[1].set_title("Predicted labels")
ax[1].legend(loc = 'upper left', ncol = 2)
fig.suptitle(method)
fig.set_size_inches((10,5))
return fig, ax
fig, ax = pca_plot(pred, "Logistic Regression")
Random Foest
As before, I will just use the default implementation.
# let's train a "simple" random forest
rf = RandomForestClassifier()
rf.fit(training_set.values, train_labels)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
pred = rf.predict(test_set.values)
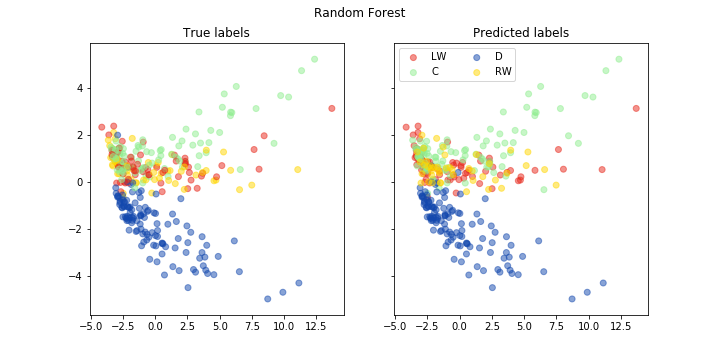
print("Accuracy of random forest is: {}".format(accuracy(np.array(pred), np.array(test_labels))))
Accuracy of random forest is: 0.6929824561403509
cmat, label_list = get_confusion_matrix(test_labels, pred)
fig, ax = plot_confusion_matrix(cmat, label_list)
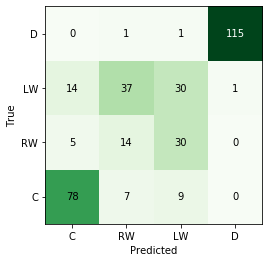
fig, ax = pca_plot(pred, "Random Forest")
Naive Bayes Classifier
For the NBC, I will again use the default implementation but assume that every variable has a Gaussian distribution. This is not ideal by any means, but is easiest to code and gives you a flavour of what it does.
# let's train a "simple" naive bayes classifier
nbc = GaussianNB()
nbc.fit(training_set.values, train_labels)
GaussianNB(priors=None, var_smoothing=1e-09)
pred = nbc.predict(test_set.values)
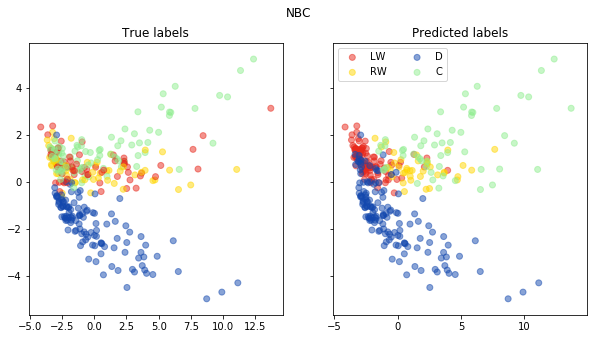
print("Accuracy of Naive Bayes classifier is: {}".format(accuracy(np.array(pred), np.array(test_labels))))
Accuracy of Naive Bayes classifier is: 0.5847953216374269
fig, ax = pca_plot(pred, "NBC")
Support Vector Machines
Here I will use the LinearSVC class; essentially we are applying a linear kernel to the data. What this
means is that essentially we are assuming that no transformation is needed to draw a hyperplane that will
separate the data.
svc = LinearSVC(max_iter=2000)
svc.fit(training_set.values, train_labels)
LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=2000,
multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,
verbose=0)
pred = svc.predict(test_set.values)
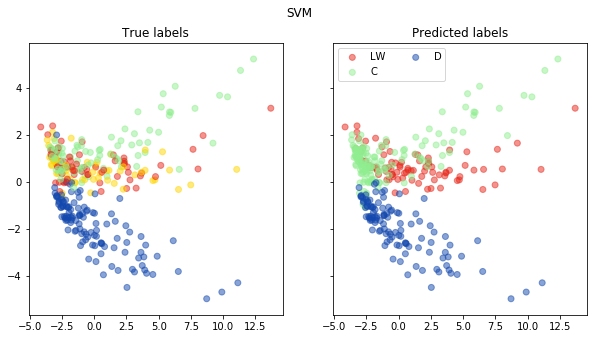
print("Accuracy of SVC is: {}".format(accuracy(np.array(pred), np.array(test_labels))))
Accuracy of SVC is: 0.7017543859649122
cmat, label_list = get_confusion_matrix(test_labels, pred)
fig, ax = plot_confusion_matrix(cmat, label_list)
plt.show()
fig, ax = pca_plot(pred, "SVM")
Revision
No method was a true outstanding performer. While the random forest classifier did have the highest level of accuracy, it was only marginally better than logistic regression.
It would be worth seeing why certain methods failed to classify a player into the correct primary position. We could go more in-depth and ask,
- Is this a case where we over-penalise ourselves (e.g. left-wing vs. right-wing players are not that different)?
- Is this a case where a player has out-of-position behaviours (e.g. a defenseman with some high goals/assists? a forward who is a defensive specialist?)
- Is there not enough game data?
Going further, we can ask…
- Are there fundamental aspects of the ML methods tested here that make it unsuitable for this problem?
- Can we do feature selection of some sort?
- What other information can we get to improve prediction? For example, does stick handed-ness have any bearing on position?
from scipy.stats import gaussian_kde
test_set_copy = test_set.copy()
test_set_copy['pred'] = rf.predict(test_set_copy)
test_to_names = pd.merge(
left = test_set_copy,
right = skaters,
how = 'inner', on = 'player_id'
)
correct = test_to_names[test_to_names['primaryPosition']==test_to_names['pred']].copy()
incorrect = test_to_names[test_to_names['primaryPosition']!=test_to_names['pred']].copy()
incorrect[['firstName', 'lastName', 'primaryPosition', 'pred']].head(5)
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
correct_gp = correct['games_played'].values
incorrect_gp = incorrect['games_played'].values
# We can create a Gaussian kernel on top of the number of games played to do some comparisons
correct_kde = gaussian_kde(correct_gp)
incorrect_kde = gaussian_kde(incorrect_gp)
num_games = np.arange(1, 801)
fig, ax = plt.subplots(1,1)
ax.plot(num_games, correct_kde.evaluate(num_games), color = '#134a8e', label = "Correct predictions")
ax.plot(num_games, incorrect_kde.evaluate(num_games), color = '#e8291c', label = "Incorrect predictions")
ax.set_xlabel("Number of games played")
ax.set_ylabel("Density")
Text(0, 0.5, 'Density')
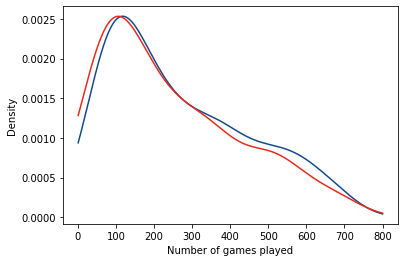
What’s interesting here is that:
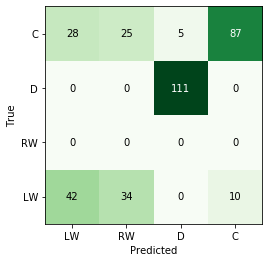
- For the random forest, mis-classifications are only found for forwards (no defensemen are ever classified as forwards and vice-versa).
- There are more winger mis-classifications (actual = RW, predicted = LW), which may imply a too-stringent classification scheme.
- This doesn’t seem to be affected by the number of games played by the players as they have similar distributions.
While we can explore the data further to explain misclassifications, I think that’s outside the scope of this post and that’s for next time…