Numba in action!
Accelerate your Numpy code with numba...
Accelerate your Numpy code with numba...
Pandas tips & tricks...
This post shows how we can use a PMF and PDF to some toy problems....
A cheat sheet for probability distributions....
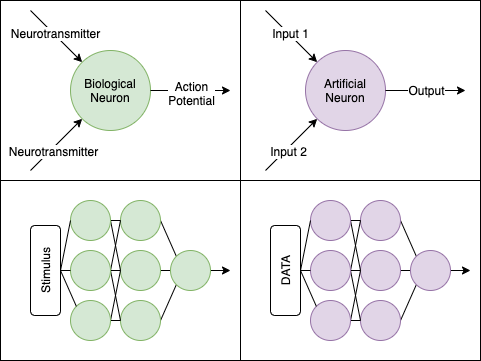
This is my intro to neural networks....
It’s Christmas, and Santa is here! He’s got his list and he’s about to see who’s been naughty or nice this year. While on his way out of the North Pole, he comes across some turbulence, and he loses his list. Rudolph tried his hardest, but to no avail. Santa is in trouble. Without his list, it’s going to take ages to visit every house in every neighbourhood, then go down the chimney to see who’s been nice or naughty....
In a previous post, I covered arguably one of the most straight-forward clustering algorithms: hierarchical clustering. Remember that any clustering method requires a distance metric to quantify how “far apart” two points are placed in some N-dimensional space. While typically Euclidean, there’s loads of ways in doing this. Generally, hierarchical clustering is a very good way of clustering your data, though it suffers from a couple of limitations: Users have to define the number of clusters The linkage criterion (UPGMA, Ward…) can have a huge effect on the cluster shapes Other clustering methods like K-means clustering also depend on the number of clusters to be determined beforehand, and it can be prone to hitting local minima....
Last time I covered a section on clustering, a group of unsupervised learning methods – so called because they are not given the class memberships of the data$$^\dagger$$. Don’t worry, I will do more posts on clustering soon. For now I wanted to give a quick overview of what supervised methods look like. For that, let’s look at the statistics of hockey players! $$\dagger$$: this is a gross generalisation. More formally, for some dataset $$\mathbf{X}$$, if we are trying to predict an output variable $$\mathbf{Y}$$, we use supervised learning methods, otherwise unsupervised learning methods....
Context From the last blog post, we saw that data can come with many features. When data gets very complex (at least, more complex than the Starbucks data from the last post), we can rely on machine learning methods to “learn” patterns in the data. For example, suppose you have 1000 photos, of which 500 are cats, and the other 500 are dogs. Machine learning methods can, for instance, read the RGB channels of the images' pixels, then use that information to distinguish which combinations of pixels are associated with cat images, and which combinations are linked to dogs....
Data is everywhere. Whether it’s political survey data, the DNA sequences of wacky organisms, nutritional profiles of our favourite foods, you name it. Data comes in various shapes and sizes, too - it can be several thousand samples with only a few features, or only a small number of examples with tons of features. For either case, and anything else in between, finding a lower-dimensional (i.e. fewer features) representation of our data is useful; however, how do we choose which features to use for capturing the essence of our data?...